Introduction:
You had a great party last night with some of your Smart Manufacturing and Robotics friends and you drank some beer. You promised each other to split the costs of the beer, but the next morning you realise you forgot that. All you have left are the bottles and caps of the beers, but don’t panic, this is where the Beerminder application comes in handy. You can simply take a picture of all caps, and the Beerminder application as a result gives you the number of beers per brand with the total value of the beers, so you can split the costs with your friends.
Beerminder is established by four students of the minor Smart Manufacturing and Robotics at The Hague University of Applied Sciences and focuses on using machine learning and deep learning to tackle this problem.
Assignment:
The main focus of Beerminder is using machine learning or deep learning on a costum dataset with beer caps. This algorithm should be accessible through a user-friendly Application Programming Interface (API), in which the user can upload an image of beer caps. The user will as a result get an image with all caps defined on it, together with a table where the caps are listed with prices.
The user will upload an image similar to the following: 
Costum Neural Network
To successfully get to the end result come up with a solution for detecting and classifying caps we made use of YOLOv3, which is a state-of-the-art, real time object detection system. YOLOv3, in comparison to other detection systems, applies a single neural network to the full image. This network divides the image into regions and predicts bounding boxes and probabilities for each region. These bounding boxes are weighted by the predicted probabilities. [1]
To make this neural network work with our beer caps, we had to make a costum dataset using LabelImg. In LabelImg you can annotate images by manually creating bounding boxes for each beer cap and LabelImg them with the right brand. We chose to do this for Amstel, Brand, Kornuit, Grolsch, Leffe, Hertog Jan, Heineken, Corona and Jupiler. For each brand we annotated roughly 60 images. After annotating, each picture gets a text file with the class number and the coordinates of the bounding boxes. In total we have a dataset of 503 images, which makes a decent dataset. A gif of our annotated data is shown down here:
This dataset is then trained in the YOLOv3 network, using Google Collab’s GPU, which is way faster than using our own GPU and it saves a lot of time installing all sorts of packages. The training process results in a weights file. This file is basically a binary file which contains the brains of our Beerminder application and could then be implemented in a machine learning program for object detection. As a result, we can use the algorithm on images to detect the nine different brands of beer caps. An example of a resulting image can be seen down here:

Application Programming Interface:
For the API we used a library in Python named Flask. This library makes it easy to make an API and run a server on your computer. A big advantage of Flask is that you need fewer lines of code to get a working API and it only needs one main file to run, which makes it easy to understand for non-experienced web developers like us. We also used some HTML code to let the API look more attractive to the user.
On the API you can upload your own image. After pressing upload, the API will show the caps that are found with a coloured bounding box around the cap. Next to the name of the cap the percentage of the predicted probability. To show a little more information about the caps we decided to also list the prices of the beers. This is all shown in a table which can be found under the resulting picture. An impression of the API is shown in the gif down here:
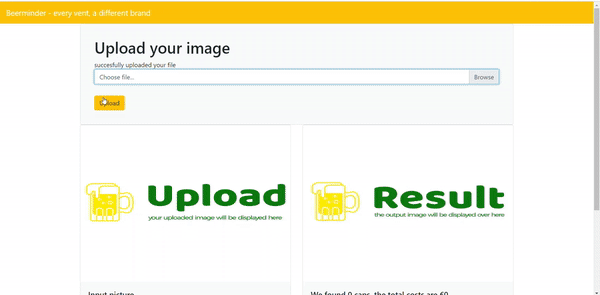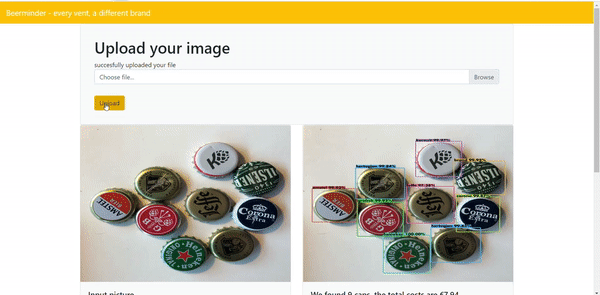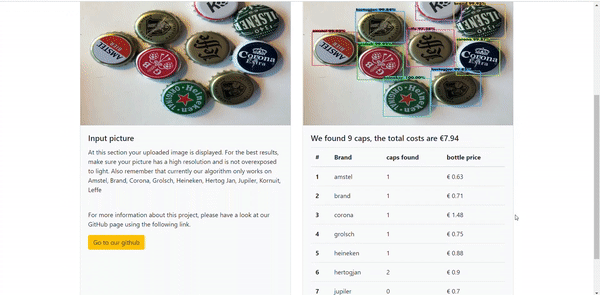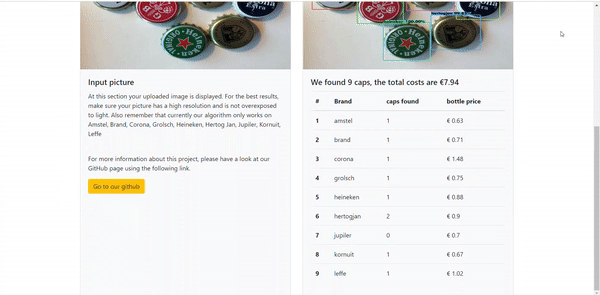
You can also access our website and try our application on www.beerminder.nl .
Points of improvement:
Right now, our YOLOv3 network is working well but it can be improved by making the dataset a lot bigger. It is now trained with approximately 500 images, but the results would even get better if our dataset has around 200 images per brand. Also, the way of making pictures is important. Take for example, pictures with a low resolution, different angle, different light intensity. These are all factors that could really improve the results. There are some ways to augment pictures in a great way.
Also, the API is now running on a server on one of our laptops. Our goal for the API is to change this to a cloud server so it can run 24/7 without needing a laptop. This would also make the API faster, more robust and a lot saver.
Literature:
| [1] | Joseph Redmon, „YOLO: Real-Time Object Detection,” YOLO, 2018. [Online]. Available: https://pjreddie.com/darknet/yolo/. [Opened April 2020]. |
Students:
Stefan Ammerlaan: https://www.linkedin.com/in/stefan-ammerlaan-a388141a6/
Sven den Exter: https://www.linkedin.com/in/sven-den-exter-3688141a6/
Jere Korpela: https://www.linkedin.com/in/jere-korpela-027/
Thijs de Knegt: https://www.linkedin.com/in/thijs-de-knegt-4b18161a6/