Students: Saskia de Wit and Pedram Kiai
[This assignment is part of Siemens’ greater project to automate twistlock handling. Due to the COVID-19 related lockdown this project assignment and the solution have been adapted to working from home, without a physical robot]
Introduction
Every year over 200 million containers are shipped throughout the world. Through the use of twistlocks these containers are safely secured together on the ship. These twistlocks are fitted onto the container during loading and removed during unloading of the ship. Currently there are approx. 2 billion twistlocks handled manually every year.
The solution
Together we’ve created an web-page based where you can upload a picture with twistlocks, cornercastings or both. The web-page returns an image with bounding boxes around these objects and some informative data on these objects. These data points are the x and y coordinates of the center of the object, the width of the bounding box and the height of this box.
These datapoints can later be used to control a robot that will bin-pick twistlocks from a variable location.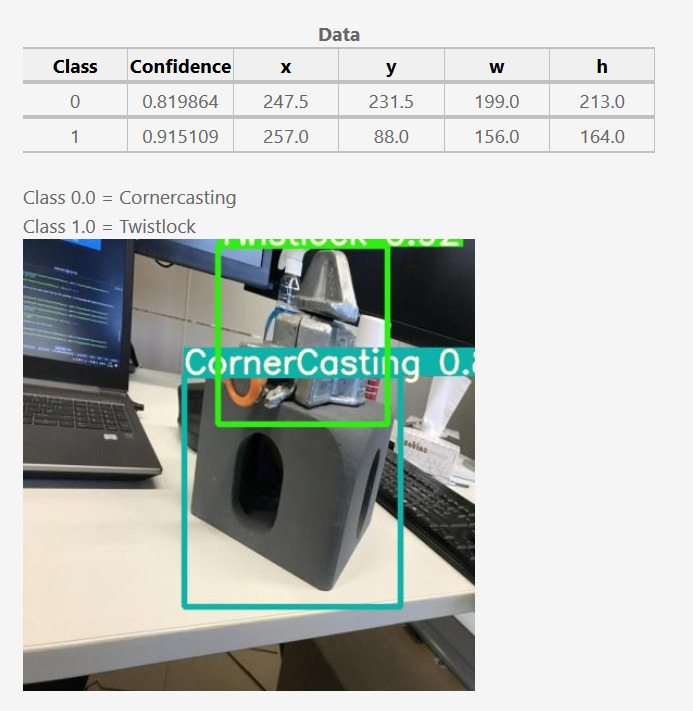
How did we do it
The web-page itself is created with a microframework called Flask. In Flask all the actions on the web-page are programmed. For instance uploading a picture and returning it to the user. The templates of these webpage are HTML and CSS based.
To use YOLO V5 we first needed to create our own dataset to train the existing model. We’ve used Roboflow to create bounding boxes on around 300 pictures. RoboFlow also automaticly augments the data to create a larger dataset. Including this augmented data the dataset was eventually 1286 images. YOLOv5 also offers a training program in Jupyter Notebook which can be called through Google Collaborate. Google Collaborate allows the engineer to run the training methods on Google hardware, as this can be a performance-heavy duty.
Through Google Collaborate different settings and models were tested, using different sizes of epochs (iterations) to get to the best result. Too many epochs means an overfitted model, too few epochs results in a not-optimal machine learning model.
With this we created our own model that is used on the webpage. This model can also be called directly by another Python program using a different image source, such as a livestream or a pre-recorded video.
In our gallery view on our webpage you are able to see results on pictures that were not used when training our model, the model has never seen these pictures before.

Conclusion
We’ve used and tried several options of machine-learning to create a recognition software for cornercastings and twistlocks. Sometimes we had a dead-end but in the end we are proud of our results and we learned a lot by doing this project. COVID-19 sometimes made it even more difficult to keep on track, but in the end we did not lose focus on our goal.
We want to thank Thijs Brilleman, Guus Paris and Mathijs van der Vegt for their support during this challenging assignment.
We also want to thank Siemens for the fun and challenging assignment and for the great communication all through the project.